学习:数据结构——邻接表
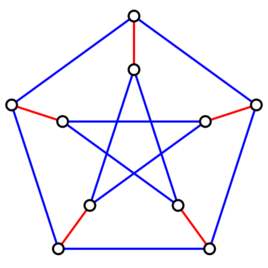
在做图论的时候,为了储存图,我们会使用邻接矩阵
就比如上面这个图,用邻接矩阵储存就是这样:
0 1 2 3 4 5 0 0 0 1 0 1 1 1 0 0 0 0 1 1 2 1 0 0 1 1 0 3 0 0 1 0 0 0 4 1 1 1 0 0 0 5 1 1 0 0 0 0 但是这样储存明显有缺点:
- 空间复杂度太大
- 时间复杂度太大
于是乎,邻接表你值得拥有
谔谔,查遍oi wiki就找到了两行解释,然后百度百科太权威看不懂
好吧,看看广大人民怎么说:首先我想说邻接表真是个巧妙的数据结构呵

邻接表
首先,邻接表跟链表有几分相像,这样就好理解邻接表了
不过我们不用链表,我们只是用数组来模拟邻接表的普通OIer
那么就有以下数组要用:
- 存第条线的起点
- 存第条线的终点
- 存第条线的权值
- 存
我其实说不清楚 - 存
其实我还是说不清楚
还有,设为边数,为点数
关于,,数组
读入的时候,就把对应的起点、终点、权值存进
关于,数组
最重要的地方来了,就是和到底是干啥的呢?
关于
数组其实是存起点为第个点的边的编号
拗口?(反正我这么觉得)
实际操作起来就是这样的:
初始化将全部初始化为
每输入一条边(假设输入的边的编号、起点、终点、权值分别为,,,),若等于,就将赋为
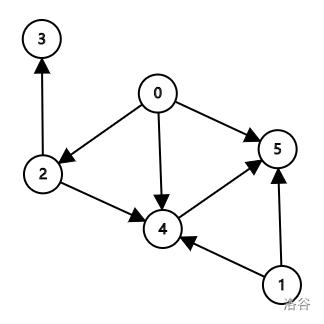
现在根据这个图(权值就看做1)
可以是这样的(反正什么顺序都一样,就字典序吧):
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 1 | 1 | 2 | 2 | 4 | |
| 2 | 4 | 5 | 4 | 5 | 3 | 4 | 5 | |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
然后,拿出数组,全部初始化为
| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| -1 | -1 | -1 | -1 | -1 | -1 |
按照步骤,读到的时候数组就是这样:
| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| 1 | -1 | -1 | -1 | -1 | -1 |
可以说,邻接表的操作方式真的很迷惑
但接下来就是更迷惑的数组了
关于
当有两条边的起点一样时(设第一个边编号为,第二个边编号为,公共的起点为,就是说 ),就发挥了作用
如果我们在这种情况下仍然用上面的操作的话,以前的自然会被覆盖掉
所以我们把存到去,再把赋为
拗口?(反正我还是这么觉得)
实际上就是这样:
初始化时数组全部初始化为
每次在输入一条边后,如果不等于,那就将赋为,再将赋为
还是接着之前的操作:
| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| 1 | -1 | -1 | -1 | -1 | -1 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|
| -1 | -1 | -1 | -1 | -1 | -1 | -1 | -1 |
按步骤操作到
| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| 2 | -1 | -1 | -1 | -1 | -1 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|
| -1 | 1 | -1 | -1 | -1 | -1 | -1 | -1 |
真的非常迷惑
但还没完
我们现在把整个弄完:
手动模拟邻接表
| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| 3 | -1 | -1 | -1 | -1 | -1 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|
| -1 | 1 | 2 | -1 | -1 | -1 | -1 | -1 |
| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| 3 | 4 | -1 | -1 | -1 | -1 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|
| -1 | 1 | 2 | -1 | -1 | -1 | -1 | -1 |
| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| 3 | 5 | -1 | -1 | -1 | -1 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|
| -1 | 1 | 2 | -1 | 4 | -1 | -1 | -1 |
| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| 3 | 5 | 6 | -1 | -1 | -1 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|
| -1 | 1 | 2 | -1 | 4 | -1 | -1 | -1 |
| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| 3 | 5 | 7 | -1 | -1 | -1 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|
| -1 | 1 | 2 | -1 | 4 | -1 | 6 | -1 |
| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| 3 | 5 | 7 | -1 | 8 | -1 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|
| -1 | 1 | 2 | -1 | 4 | -1 | 6 | -1 |
上面有一个细节,就是
好了,我们现在存好数组了,那么如何读取呢?
这个费尽心思搞出的储存方式,一定有很好的性能(简洁的算法往往带来低效,复杂的算法往往带来高效)
读取
我们来看,当我们需要遍历以一个点为起点的所有边,我们怎样来读取信息
以为起点为样例:(为了演示就只能用图片了)

黄的表示起点,蓝的表示边的编号,红的表示下一条边的储存位置,黑的表示读取终止
其中我们从数组的第项读起
下一个边的位置便是当前读到的边的编号
直到读到为止

你会发现,读取的效率非常高,因为读取都是一连串读下来,次次读的都是数据
而且空间占用很小
对比一下邻接矩阵,邻接矩阵无地自容